How to Achieve Hyperscale Capacity Efficiency with Unified AI Agents
Introduction
When your infrastructure serves billions of users daily, even a 0.1% performance regression can waste megawatts of power—enough to power hundreds of thousands of homes. At Meta, the Capacity Efficiency Program solved this challenge by building a unified AI agent platform that automates both detecting and fixing performance issues. This guide explains how you can replicate that approach in your own organization, turning a team of efficiency engineers into a scalable, self-sustaining engine that recovers power and frees up human talent for innovation.

What You Need
- Engineering Team: A dedicated group with expertise in performance optimization, system architecture, and machine learning.
- Monitoring & Observability Tools: Existing systems to track resource usage (CPU, memory, power) across your fleet.
- Regression Detection System: A tool like Meta’s FBDetect that automatically catches performance regressions in production.
- CI/CD Pipeline: Automated deployment infrastructure that can hold or rollback changes.
- Code Repository Access: Ability to integrate with version control and pull request systems.
- Domain Experts: Senior efficiency engineers whose knowledge will be encoded into the AI agents.
- Compute Resources: Sufficient cluster capacity to run AI inference and training for agent models.
Step-by-Step Guide
Step 1: Define Your Efficiency Strategy — Defense and Offense
Hyperscale efficiency requires two complementary approaches. On the defense side, you must catch regressions that slip into production and quickly mitigate them. On the offense side, you proactively identify opportunities to optimize existing systems. Document both workflows and identify where human intervention creates bottlenecks. At Meta, engineers were spending up to 10 hours per manual investigation — a clear signal that automation was needed.
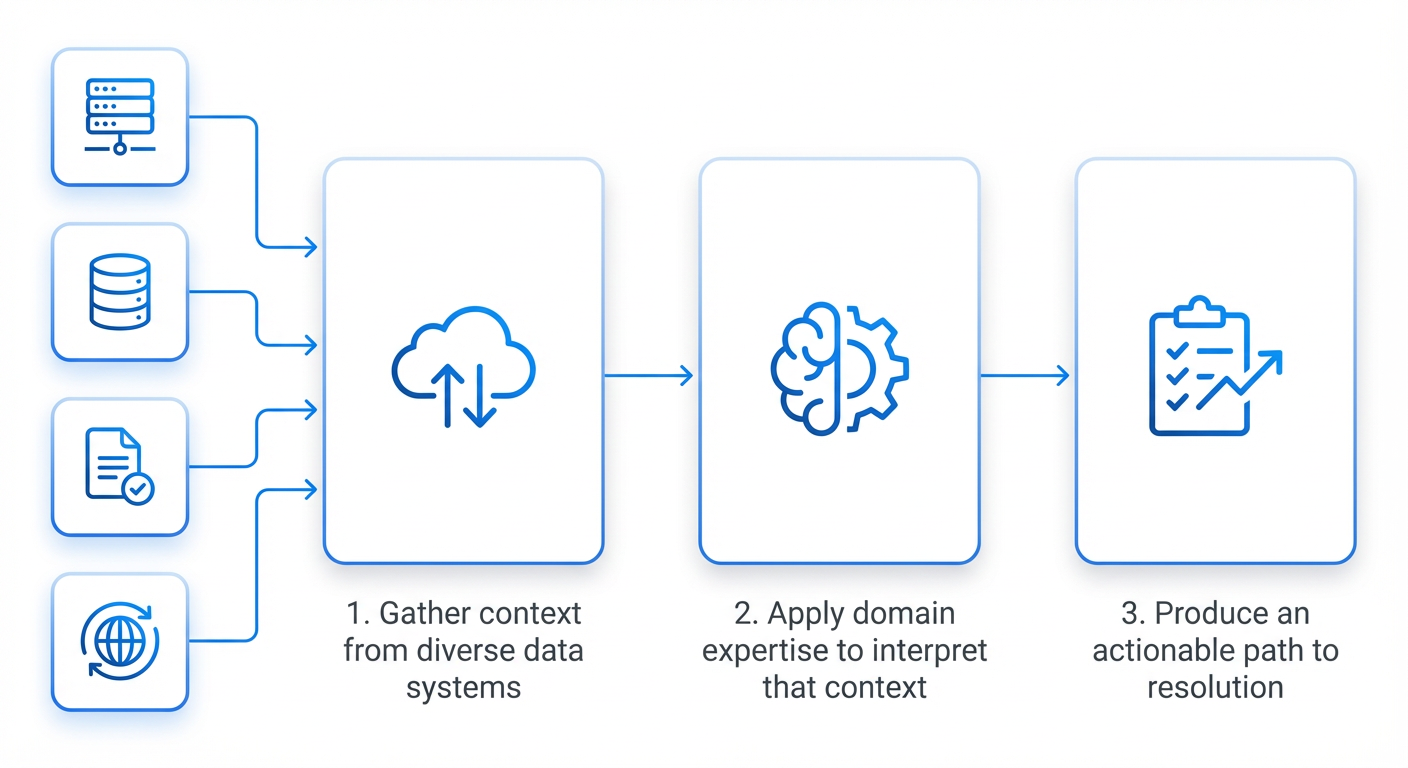
Step 2: Build a Unified AI Agent Platform with Standardized Tool Interfaces
Create a platform that acts as a single control plane for all efficiency tasks. The key is to standardize the interface every tool exposes so that AI agents can interact with them without custom adapters. This platform should allow agents to call monitoring APIs, query databases, submit code changes, and deploy fixes. Meta’s platform encodes domain expertise into reusable, composable skills — think of them as building blocks that can be assembled into complex workflows.
Step 3: Encode Domain Expertise into Reusable, Composable Skills
Work with your senior efficiency engineers to capture their mental models, heuristics, and investigation patterns. Turn these into discrete skills that the AI platform can call. For example, a skill might be “check if a recent configuration change caused a CPU spike” or “compare two versions of a microservice to find differences in memory allocation.” Each skill is a small, testable unit of automation. Over time, you build a library that any agent can reuse, scaling expertise across the organization without scaling headcount.
Step 4: Automate Regression Detection and Root-Cause Analysis
Use your existing regression detection system (e.g., a tool akin to FBDetect) to continuously monitor production metrics. When a regression is detected, trigger AI agents that automatically execute a diagnosis workflow. The agent runs through the encoded skills: it queries source code history, correlates with recent deployments, and isolates the responsible commit. Meta compressed this process from ~10 hours to ~30 minutes. The goal is to have a ready-to-review report (or even a mitigation) before a human engineer even wakes up.
Step 5: Automate Opportunity Resolution (Offense)
Proactively scan for efficiency improvements by running agents across your codebase and infrastructure. These agents look for patterns known to be inefficient — like unnecessary loops, large database queries, or suboptimal caching. When an opportunity is found, the agent generates a ready-to-review pull request with the change, description, and estimated power savings. This automation handles the “long tail” of small optimizations that engineers would never get to manually.
Step 6: Scale Without Proportionally Scaling the Team
As your agent library grows, you can apply it to more product areas. The key metric is megawatts (MW) of power recovered per engineer. By automating both detection and fix generation, your team can handle an increasing volume of wins. Meta reports recovering hundreds of MW — enough to power hundreds of thousands of homes — without adding headcount at the same rate. Track metrics like “investigation time saved” and “wins per agent” to prove the impact.
Step 7: Build a Self-Sustaining Efficiency Engine
The ultimate goal is a system that continuously learns. Implement feedback loops: when a human engineer corrects or approves an agent’s output, use that signal to improve the underlying skills. Periodically retire skills that are no longer effective and add new ones based on emerging trends. Over time, your platform becomes smarter, faster, and more autonomous, handling the vast majority of efficiency tasks without human intervention.
Tips for Success
- Start with a Pilot Product Area: Choose a well-understood system with clear performance metrics. Prove the concept before expanding.
- Involve Domain Experts Early: The quality of your encoded skills determines the success of the agents. Make knowledge capture a team sport.
- Integrate Deeply with Existing Tools: Don’t reinvent the wheel. Use your current monitoring, CI/CD, and incident management systems as the base.
- Measure What Matters: Besides power saved, track time saved per investigation, accuracy of agent diagnoses, and reduction in open performance tickets.
- Iterate Quickly: Release new skills in small batches. Monitor for false positives or missed cases and refine accordingly.
- Celebrate Automation Wins: Share success stories — for example, “Agent X found and fixed a 0.5% regression in service Y, saving 2 MW.” This builds internal momentum.
By following these steps, you can create your own capacity efficiency program that leverages unified AI agents to optimize performance at hyperscale. The result: less wasted energy, more innovation time, and a team that scales with the demands of your growing infrastructure.
Related Articles
- Debian's Forky Release Mandates Reproducible Builds: A Q&A on Enhanced Security
- Exploring Fedora KDE Plasma Desktop 44: Key Updates and Enhancements
- Fedora Asahi Remix 44: Everything You Need to Know
- 7 Essential Updates for Fedora Atomic Desktops in Fedora 44
- Reviving Unity: How a Community Developer Recreated Ubuntu's Iconic Desktop with Modern Tools
- Top 5 Enhancements in Terraform 1.15: Dynamic Module Sources and Deprecation Features
- HashiCorp Launches Terraform Enterprise 2.0 to Revolutionize Large-Scale Infrastructure Operations
- How to Protect Your Linux System from the Compromised Cemu Wii U Emulator Builds