Mastering AI Hardware Diversity: How KernelEvolve Automates Performance Optimization at Meta
Meta's Ranking Engineer Agent already autonomously designs and experiments with ranking models. But to run those models at scale across a diverse fleet of hardware—from NVIDIA and AMD GPUs to custom MTIA chips and CPUs—engineers must write optimized kernel code for each chip and model. Hand-tuning these low-level instructions no longer scales. Enter KernelEvolve, an agentic system that treats kernel optimization as a search problem, using large language models (LLMs) and automated evaluation to find the best performing kernels in hours instead of weeks. This Q&A explores how KernelEvolve works, its performance gains, and its broader impact on AI infrastructure.
- What is KernelEvolve and why did Meta build it?
- How does KernelEvolve treat kernel optimization differently from traditional methods?
- What types of hardware and programming languages does KernelEvolve support?
- How much performance improvement did KernelEvolve achieve for Meta's models?
- How does KernelEvolve combine LLMs with automated search to generate kernels?
- Can KernelEvolve be applied to AI models beyond ads ranking?
- Why are custom kernels essential for production workloads at Meta's scale?
1. What is KernelEvolve and why did Meta build it?
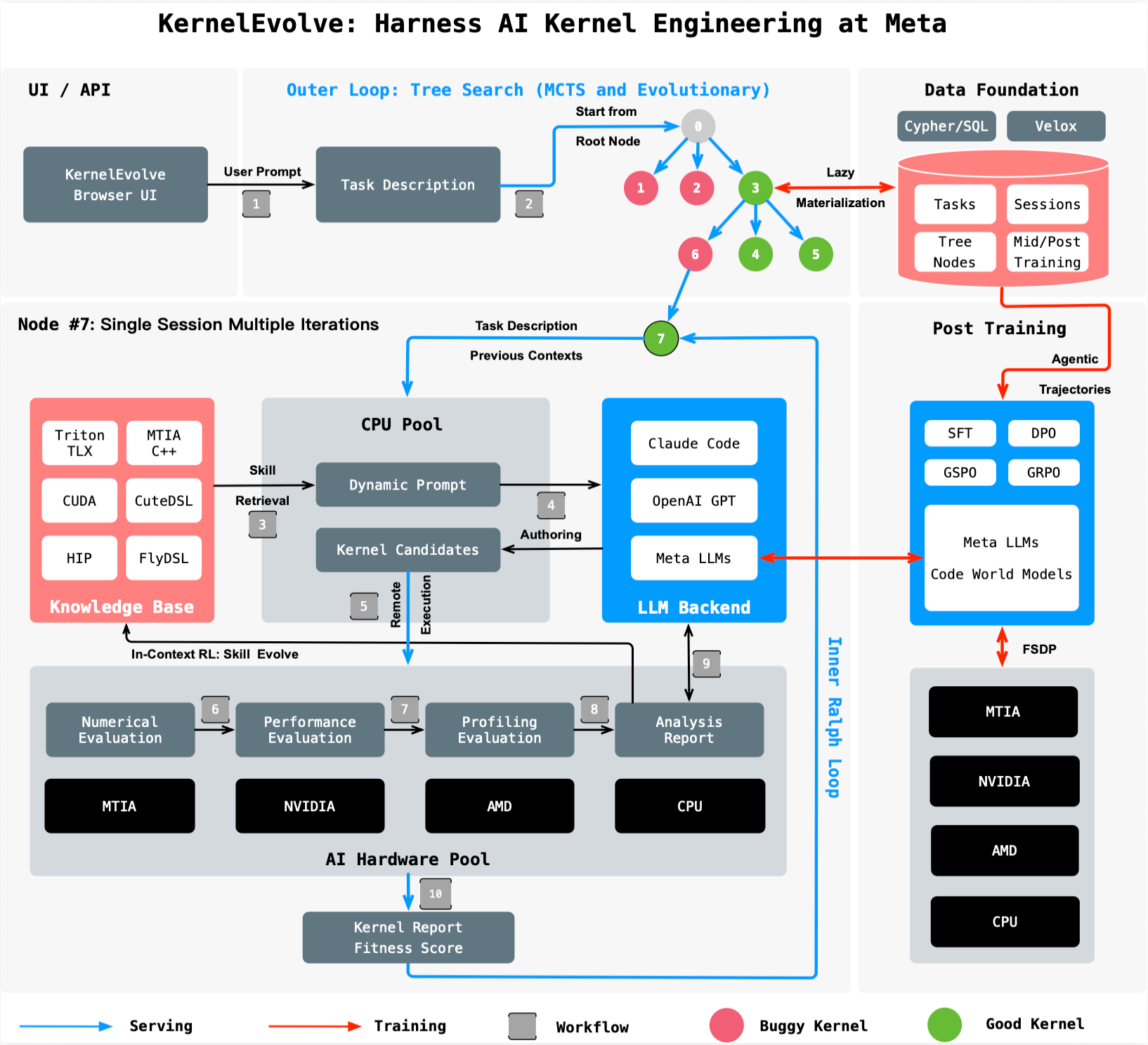
KernelEvolve is an agentic kernel authoring system developed by Meta to automatically optimize the low-level software that translates high-level machine learning operations into chip-specific instructions. Meta operates a heterogeneous fleet of accelerators—NVIDIA GPUs, AMD GPUs, custom MTIA silicon, and CPUs—each requiring tailored kernels. With every new chip generation and model architecture, kernel experts previously had to hand-tune custom operators beyond standard libraries like GEMMs and convolutions. This manual approach no longer scales as the product of models and hardware types grows exponentially. KernelEvolve automates the tedious process of profiling, optimizing, and debugging across different hardware, compressing weeks of expert work into hours. It was built as an agent within Meta’s Ranking Engineer Agent to accelerate ads ranking innovation, but its design is generally applicable to any AI model that needs efficient kernel code.
2. How does KernelEvolve treat kernel optimization differently from traditional methods?
Instead of relying on human intuition and manual trial-and-error, KernelEvolve frames kernel optimization as a search problem. It uses a purpose-built job harness that evaluates each candidate kernel on real hardware, collecting diagnostics like throughput, memory usage, and latency. These metrics are fed back to an LLM, which then proposes modifications to the kernel code. The system runs hundreds of iterations, exploring a wide range of optimizations—often exceeding what a human expert can manually consider. This automated search loop continuously improves performance, adapts to new hardware, and runs in parallel across many candidates. Traditional methods would require kernel experts to hand-write and benchmark each variant, a slow and resource-intensive process. KernelEvolve’s approach is both faster and more thorough, uncovering optimizations that even experienced engineers might miss.
3. What types of hardware and programming languages does KernelEvolve support?
KernelEvolve is built to operate across Meta’s entire infrastructure, which includes both public and proprietary hardware: NVIDIA GPUs, AMD GPUs, Meta’s custom MTIA chips, and general-purpose CPUs. To target these diverse accelerators, the system can generate kernels in high-level domain-specific languages (DSLs) such as Triton, Cute DSL, and FlyDSL, as well as low-level languages like CUDA, HIP, and MTIA C++. This multilingual capability ensures that whether a model runs on an NVIDIA H100, an AMD MI300, or Meta’s own silicon, KernelEvolve can produce optimized code. The broad applicability means that teams working on ranking models, generative AI, or any other workload can benefit from automated kernel tuning without mastering every hardware platform.
4. How much performance improvement did KernelEvolve achieve for Meta's models?
KernelEvolve delivered significant gains on production workloads. For the Andromeda Ads model running on NVIDIA GPUs, inference throughput improved by over 60%. On Meta’s custom MTIA chips, an ads model saw training throughput increase by more than 25%. These improvements directly translate to faster model experimentation, reduced latency for users, and lower infrastructure costs. The system has consistently outperformed kernels hand-tuned by human experts, demonstrating that automated search can discover optimizations that even the best engineers might not find manually. Beyond these headline numbers, KernelEvolve’s ability to rapidly optimize across hardware generations ensures that Meta can keep scaling its AI services without proportional increases in engineering effort.
5. How does KernelEvolve combine LLMs with automated search to generate kernels?
KernelEvolve uses a two-part architecture. First, a large language model (LLM) acts as the “programmer,” proposing candidate kernel implementations based on a high-level description of the operation and hardware target. Second, a job harness compiles and executes each candidate on the actual hardware, collecting performance diagnostics. These results are fed back to the LLM, which then refines the kernel in an iterative loop. The system runs hundreds of these iterations in parallel, using the search space of possible code transformations. By combining the creative generation power of LLMs with rigorous, automated evaluation, KernelEvolve can explore optimizations like loop unrolling, memory coalescing, and instruction-level parallelism far more efficiently than a human. The continuous feedback ensures that only empirically better solutions survive, driving performance beyond baseline implementations.
6. Can KernelEvolve be applied to AI models beyond ads ranking?
Absolutely. Although initially deployed within Meta’s Ranking Engineer Agent for ads ranking models, KernelEvolve is designed as a general-purpose agentic kernel authoring system. Its core capability—automatically optimizing kernels for heterogeneous hardware using LLM-guided search—applies to any AI model that requires efficient low-level code. This includes recommendation systems, natural language processing models, computer vision, generative AI assistants, and more. The system’s flexibility to generate kernels in multiple DSLs and low-level languages makes it hardware-agnostic. Meta’s infrastructure serves billions of AI-powered experiences daily; KernelEvolve can optimize the infrastructure underpinning all of them. The research paper detailing KernelEvolve will appear at ISCA 2026, highlighting its broad relevance to computer architecture and systems optimization communities.
7. Why are custom kernels essential for production workloads at Meta's scale?
Standard libraries like cuBLAS provide efficient implementations for common operations such as general matrix multiplications (GEMMs) and convolutions. However, production workloads—especially in ads ranking—often require many custom operators that are not covered by vendor libraries. These operators may involve unique data layouts, fusion patterns, or numerical precision requirements. Moreover, with the proliferation of hardware types (NVIDIA, AMD, MTIA) and generations, hand-tuning each custom operator becomes impractical. Even a single model can involve dozens of custom kernels, each needing optimization for multiple chips. Without automated solutions like KernelEvolve, engineering teams would be forced to either accept suboptimal performance or allocate scarce kernel expert time to manually tune each variant. By automating the creation and tuning of custom kernels, KernelEvolve enables Meta to maintain high efficiency across its entire fleet without slowing down innovation.
Related Articles
- How to Diagnose and Fix a CUBIC Congestion Control Bug in QUIC
- Linux Kernel Maintainer Deploys AI Fuzzing Tools 'gkh_clanker' to Hunt Bugs
- Fedora's Proactive Defense Against Emerging Linux Kernel Flaws
- Navigating the PATH Maze: Experts Caution Users on Critical Directory Configuration Blunders
- Linux Kernel Memory Management Faces Leadership Transition as Longtime Maintainer Steps Down
- 9 Essential Highlights of Fedora Linux 44: What Every User Needs to Know
- Scaling Infrastructure Operations with Terraform Enterprise 2.0: Key Enhancements and Capabilities
- HashiCorp Launches Terraform Enterprise 2.0: Massive Infrastructure Overhaul for Scaling Teams